Las redes
inalámbricas hoy en día son de gran utilidad, ya que son uno de los medios de
comunicación más importantes con los que podemos contar. Estas cada día han
venido creciendo con la finalidad de tener cobertura o señal más expansible
esto va desde señales wifi hasta señales de móviles como lo es la 4G.
La nueva era de
las tecnologías inalámbricas son de gran importancia ya que con este tipo de
tecnologías podremos estar comunicados desde cualquier lugar siempre y cuando
exista un tipo de cobertura de este tipo de tecnologías.
Cada tipo de
tecnología usa un modo distinto de transmisión y por supuesto un modo distinto
de cobertura o alcance, en algunas tecnologías la cobertura es mayor como lo es
la 4G. Por lo general este tipo de tecnologías son de expansión muy amplia lo
que implica tener un mundo con una mejor comunicación.
Hoy día, las
redes de sensores inalámbricas (WSN) son de gran ayuda para el monitoreo de
actividades, de empresas, fabricas, oficinas u hogares, para detectar cambios en el entorno y establecer comunicación que pueden ser
empleadas por las personas para trabajar a través de nodos de interconexiones a
una red o a través de internet por medio de accesos punto a punto como las WPAN
de corto alcance y multipuntos como “BlueTooth”.
Una red de
transporte, también denominada (red troncal), "nucleo de red" o
(backbone) tiene como objetivo concentrar el tráfico de información que
proviene de las redes de acceso para llevarlo a mayores distancias
Tradicionalmente
su arquitectura y sus características particulares estaban subordinadas al tipo
de información que se deseaba transportar y a las características de las redes
de acceso utilizadas. Así, por ejemplo, existen redes de transporte de señal de
televisión (para el servicio convencional de difusión de televisión), redes de
transporte de televisión por cable, múltiples tipos de redes de transporte de
datos dependientes del servicio de datos en cuestión, redes de transporte de
telefonía fija y redes de transporte decomunicaciones móviles. Sin embargo, la
llegada de la digitalización comenzó un proceso de convergencia en las redes de
transporte para hacerlas potencialmente capaces de transportar cualquier tipo
de información, independientemente de su origen. A este proceso contribuyó
también el uso masivo de la fibra óptica como el medio físico de preferencia
para el transporte. A lo largo de este proceso han ido apareciendo una serie de
tecnologías digitales para su aplicación en el transporte: X25, Frame Relay,
SDH,ATM, cada una de ellas orientada inicialmente a solventar problemas
específicos en arquitecturas específicas de transporte y que han tenido
diferentes períodos de éxito y decadencia.
La llegada de
la conmutación de paquetes y del paradigma de Internet, con el éxito de los
protocolos IP como la base del transporte masivo de datos, introdujo una nueva
cuestión al plantear si las redes de transporte debían o no tener un grado
significativo de inteligencia en su núcleo central o si esta inteligencia se
debía encontrar en los bordes de la red de transporte. La cuestión es muy
relevante pues se pretende que las nuevas redes de transporte sean lo más
transparentes posibles frente al despliegue de nuevasaplicaciones de interés
para los usuarios, es decir, que sean válidas para cualquier nueva aplicación
sin cambios significativos y sobre todo sin inversiones y retardos que puedan
impedir cumplir las expectativas de los usuarios. Las redes de nueva generación
en su parte de transporte darán respuesta a esta cuestión.
Cuando se
configura una interfaz del router activa con una dirección IP y una máscara de
subred, automáticamente se crean dos entradas en la tabla de enrutamiento. En
la ilustración, se muestran las entradas de la tabla de enrutamiento en el R1
para la red conectada directamente 192.168.10.0. Estas entradas se agregaron de
forma automática a la tabla de enrutamiento cuando se configuró y se activó la
interfaz GigabitEthernet 0/0. Las entradas contienen la siguiente información:
Origen de la
ruta
El origen de la
ruta se rotula como “A” en la ilustración. Identifica el modo en que se
descubrió la ruta. Las interfaces conectadas directamente tienen dos códigos de
origen de la ruta.
C: identifica
una red conectada directamente. Las redes conectadas directamente se crean de
forma automática cuando se configura una interfaz con una dirección IP y se
activa.
L: identifica
que la ruta es link-local. Las redes link-local se crean de forma automática
cuando se configura una interfaz con una dirección IP y se activa.
Red de destino
La red de
destino se rotula como “B” en la ilustración. Identifica la dirección de la red
remota.
Interfaz de
salida
La interfaz de
salida se rotula como “C” en la ilustración. Identifica la interfaz de salida
que se debe utilizar al reenviar paquetes a la red de destino.
Nota: las
entradas de la tabla de enrutamiento de link-local no aparecían en las tablas
de enrutamiento antes de la versión 15 de IOS.
En general, los
routers tienen varias interfaces configuradas. La tabla de enrutamiento
almacena información sobre las rutas conectadas directamente y las remotas. Tal
como ocurre con las redes conectadas directamente, el origen de la ruta
identifica cómo se descubrió la ruta. Por ejemplo, los códigos comunes para las
redes remotas incluyen lo siguiente:
S: indica que
un administrador creó la ruta manualmente para llegar a una red específica.
Esto se conoce como “ruta estática”.
D: indica que
la ruta se obtuvo de forma dinámica de otro router mediante el protocolo de
enrutamiento de gateway interior mejorado (EIGRP).
O: indica que
la ruta se obtuvo de forma dinámica de otro router mediante el protocolo de
enrutamiento Open Shortest Path First (OSPF).
Los nodos no
tienen un conocimiento de la topología de la red, deben descubrirla. La idea
básica es
que cuando un
nuevo nodo, al aparecer en una red, anuncia su presencia y escucha los anuncios
broadcast de
sus vecinos. El nodo se informa acerca de los nuevos nodos a su alcance y de la
manera de
encaminarse a través de ellos, a su vez, puede anunciar al resto de nodos que
pueden ser
accedidos desde
él. Transcurrido un tiempo, cada nodo sabrá que nodos tiene alrededor y una o
más
formas de
alcanzarlos.
Los algoritmos
de enrutamiento en redes de sensores inalámbricas tienen que cumplir las
siguientes
normas:
• Mantener una
tabla de enrutamiento razonablemente pequeña
• Elegir la
mejor ruta para un destino dado (ya sea el más rápido, confiable, de mejor
capacidad o la
ruta de menos coste)
• Mantener la
tabla regularmente para actualizar la caída de nodos, su cambio de posición o
su
aparición
• Requerir una
pequeña cantidad de mensajes y tiempo para converger
MODELOS DE
ENRUTAMIENTO
Existen varios
tipos de protocolos de enrutamiento.
Protocolo de
Difusión directa (modelo de un salto)
Este es el
modelo más simple y representa la comunicación directa. Todos los nodos en la
red
transmiten a la
estación base. Es un modelo caro en términos de consumo energético, así como
inviable porque
los nodos tienen un rango de transmisión limitado. Sus transmisiones no pueden
siempre
alcanzar la estación base, tienen una distancia máxima de radio, por ello la
comunicación
directa no es
una buena solución para las redes inalámbricas.
Modelo
Multisalto (multihops)
En este modelo,
un nodo transmite a la estación base reenviando sus datos a uno de sus vecinos,
el
cual está más
próximo a la estación base, a la vez que este enviará a otro nodo más próximo
hasta
que llegue a la
mota base. Entonces la información viaja de la fuente al destino salto a salto
desde
un nodo a otro
hasta que llega al destino. En vista de las limitaciones de los sensores, es
una
aproximación
viable. Un gran número de protocolos utilizan este modelo, entre ellos todos
los
MultiHop de
Tmote Sky y Telos: MultiHop LQI, MintRoute.
Modelo
esquemático basado en clústeres
Algunos
protocolos usan técnicas de optimización para mejorar la eficacia del modelo
anterior. Una
de ellas es la
agregación de datos usada en todos los protocolos de enrutamiento basados en
clústeres. Una
aproximación esquemática rompe la red en capas de clústeres. Los nodos se
agruparán en
clústeres con una cabeza, la responsable
de enlutar desde ese clúster a las cabezas de
otros clústeres
o la estación base. Los datos viajan desde un clúster de capa inferior a uno de
capa
superior.
Aunque, salta de uno a otro, lo está haciendo de una capa a otra, por lo que
cubre mayores
distancias.
Esto hace que, además, los datos se transfieran más rápido a la estación base.
Teóricamente,
la latencia en este modelo es mucho menor que en la de MultiHop. El crear
clústeres
provee una
capacidad inherente de optimización en las cabezas de clúster. Por tanto, este
modelo
será mejor que
los anteriores para redes con gran cantidad de nodos en un espacio amplio (del
orden
de miles de
sensores y cientos de metros de distancia).
Protocolos centrados en el dato (Datacentric)
Si tenemos un
número enorme de sensores, es difícil identificar de que sensor queremos
obtener un
dato. De una
determinada zona. Una aproximación es que todos los sensores envíen los datos
que
tengan. Esto
causa un gran despilfarro de energía.. En este tipo de protocolo, se solicita
el dato de
una zona y
espera a que se le remita. Los nodos de la zona negocian entre ellos la
información mas
válida. Solo
esta es enviada, con el consiguiente ahorro de energía.
Protocolo
basado en localización
Se explota la
posición de los sensores para encaminar los datos en la red.
Una red de
sensores inalámbricos (WSN) es una red inalámbrica que consiste en dispositivos
distribuidos de forma inalámbrica en distintos puntos espaciados que utilizando
sensores para monitorear condiciones físicas o ambientales de un lugar en
específico o campo de trabajo. Esta clase de redes se caracterizan por su
facilidad de despliegue y por ser auto configurables, convirtiéndose en todo
momento en emisor, receptor y ofrecer servicios de encaminamiento entre nodos
sin visión directa, así como registrar datos referentes a los sensores locales
de cada nodo.
Las redes
inalámbricas de sensores pueden llegar a tener múltiples aplicaciones, en
distintos campos de la vida del hombre como son en la seguridad, en el medio
ambiente, la industria, la agricultura o la practica militar, etc.
Existen varios
estudios dedicados al análisis de aspectos relacionados con el comportamiento
de TCP en los entornos móviles En ellos se pone de manifiesto el bajo
rendimiento del protocolo en diferentes entornos inalámbricos y se proponen
estrategias para mejorarlo. A continuación, se resumen algunos protocolos que
se han propuesto para mejorar el comportamiento del protocolo TCP en enlaces
inalámbricos.
• Protocolos de
Nivel de Enlace: Aparecen varias propuestas en la bibliografía de protocolos
para dar fiabilidad al nivel de enlace. Éstos utilizan básicamente dos
técnicas: la corrección de errores utilizando técnicas tipo Forward Error
Correction (FEC); y la retransmisión como respuesta a mensajes tipo Automatic
Request Repeat (ARQ). Entre estas soluciones se encuentra CDMA, TDMA y AIRMAIL.
Estos protocolos intentan esconder las pérdidas a TCP, no obstante, estas
soluciones no aseguran que se resuelvan los errores satisfactoriamente. Por lo
tanto, pueden interaccionar los mecanismos propios de TCP con los de
recuperación a nivel de enlace (tales como temporizadores de retransmisión y
reconocimientos duplicados), produciéndose retransmisiones a nivel de
transporte de paquetes que pueden haber sido retransmitidos previamente por los
mecanismos de nivel de enlace.
Mecanismos
de Solución:
• Protocolos
con conexión partida: Son aquellos que dividen en dos partes la conexión TCP
establecida, independizando la parte fija de la parte móvil. En estas
soluciones se rompe la semántica extrema a extremo de TCP. En la parte móvil se
define un protocolo específico. En [YaB94] se proponen dos protocolos, en uno
se usa TCP y en el otro se usa un protocolo de repetición selectiva sobre UDP.
El estudio del impacto de traspasos en ambas soluciones concluye en que no se
obtiene mejora en el segundo de los casos. Otro estudio [BPS97] presenta una
optimización de retransmisión selectiva en TCP con el que sí que se obtienen
mejoras significativas en entornos erróneos. En [BaB95, BaB97] se presenta el
protocolo Indirect-TCP. Éste utiliza el protocolo TCP estándar en ambas
conexiones (la de la parte fija y la de la parte móvil).
Los
inconvenientes de esta solución son los inherentes al propio protocolo TCP en
entornos móviles, ya que la interacción de los mecanismos contra la congestión
interfiere de la misma forma. Finalmente, M-TCP, presentado en [BrS97] divide
la conexión fija y móvil sin perder la semántica extrema a extremo de TCP. Esta
propuesta es adecuada para solucionar los problemas de las desconexiones
temporales debido a la movilidad, más que al efecto de los errores.
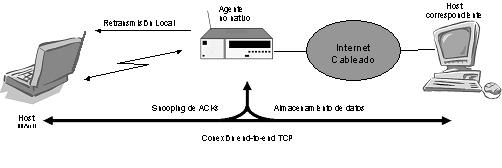
• Protocolo
“snoop” [BSK95]: Ésta es una solución híbrida entre las dos anteriores. Está
diseñado para mejorar el comportamiento del protocolo en los casos de
transferencia de datos de fijo a móvil (para el caso inverso deben añadirse
mecanismos de reconocimiento negativo). Este protocolo introduce un módulo en
la estación base, de forma que monitoriza la conexión TCP en ambas direcciones
y guarda en “cache” los segmentos que han sido enviados y que no han sido
reconocidos todavía. Si el agente detecta reconocimientos duplicados, éste los
elimina y retransmite el paquete. De esta forma, la fuente TCP no detecta la
pérdida del segmento.
Algunos
inconvenientes de este protocolo son la memoria necesaria para el almacenaje de
los paquetes y la complicación de la gestión de traspasos. No obstante, los más
importantes son, por una parte, el hecho de que los reconocimientos deben
seguir el mismo camino que los datos (sería el caso de varios enlaces móviles
en la topología de la red o en topologías asimétricas).
• Protocolos de
Notificación explícita: Basado en diferenciar las pérdidas debidas a congestión
o a errores. Una vez diferenciadas, se notifica al emisor que las pérdidas son
debidas a una causa o a la otra, y se actúa en consecuencia. En [BKV97] se
presenta el esquema Explicit Bad State Notification (EBSN), que se basa en la
notificación de estados de error en caso de que no se reciban reconocimientos
durante un cierto tiempo. Con este método se evitan, básicamente, los
inconvenientes del algoritmo debackoff exponencial tras periodos de desconexión
o altas tasas de error.
TCP usa control
de flujo para evitar que un emisor envié datos de forma más rápida de la que el
receptor puede recibirlos y procesarlos. El control de flujo es un mecanismo
esencial en redes en las que se comunican computadoras con distintas
velocidades de transferencia. Por ejemplo, si una PC envía datos a un
dispositivo móvil que procesa los datos de forma lenta, el dispositivo móvil
debe regular el flujo de datos.
TCP usa una
ventana deslizante para el control de flujo. En cada segmento TCP, el receptor
especifica en el campo receive window la cantidad de bytes que puede almacenar
en el buffer para esa conexión. El emisor puede enviar datos hasta esa
cantidad. Para poder enviar más datos debe esperar que el receptor le envié un
ACK con un nuevo valor de ventana.
Receptor lee
más despacio que lo que recibe (. . .)
El método
utilizado por TCP para control de la congestión es el basado en la regulación
del tráfico inyectado a la red. Esto supone que implementa funciones que le
permiten estudiar cuándo es posible enviar más tráfico por el enlace, y cuándo
se ha superado la capacidad del mismo y se debe disminuir la carga.
TCP emplea 4
algoritmos relacionados entre sí a los efectos de efectuar el control de
congestión. Ellos son conocidos con slow start, congestion avoidance, fast
retransmit y fast recovery.
Slow-start es
un algoritmo de control de congestión del protocolo TCP.Ni el emisor ni el
receptor tienen forma de saber cuál es el máximo volumen de datos que puede
transmitir la red, ninguno tiene información sobre los elementos de red que
transmitirán la información. Si la red se satura comenzará a descartar
paquetes, que tendrán que ser retransmitidos, lo cual puede incrementar aún más
la saturación de la red. La solución que plantea este algoritmo, consiste en
comenzar enviando un volumen de datos pequeño, que se irá aumentando hasta que
la red se sature, en cuyo caso se reducirá la tasa de envío para reducir la
saturación.
Para esto se
cuenta con tres variables de estado del protocolo. Estas son cwnd (congestión
window), que controla del lado de la fuente la cantidad de datos que se puede
enviar sin haber recibido un ACK, rwnd (receiver’s advertised window) que
indica la cantidad de datos que puede recibir el destino y ssthresh (slow start
threshold) que indica en qué fase de control de congestión se encuentra el
transmisor (slow start si es mayor que cwnd o congestion avoidance si es menor;
de ser iguales, se puede utilizar cualquiera de los dos algoritmos).
El mínimo de
cwnd y rwnd gobierna la transmisión.
El algoritmo
slow start es utilizado al comienzo de una transmisión a los efectos de que TCP
pueda testear la red y conocer su capacidad evitando congestionarla. También es
utilizado en el momento de recuperación ante la pérdida de algún segmento,
indicada por timeout. Luego del three-way handshake, el tamaño de la ventana
inicial de envío (IW: initial window) debe ser menor o igual que 2 x SMSS1 bytes y no mayor a dos segmentos.
El valor de
ssthresh debería ser lo más alto posible al comienzo y deberá reducirse en caso
de congestión. Durante la fase slow start se aumenta cwnd en a lo sumo SMSS
bytes por cada ACK recibido de datos nuevos entregados al receptor. Esta fase
culmina cuando cwnd alcanza a ssthresh o cuando se detecta congestión.
5.4.2 El problema de movilidad con TCP Los problemas existentes se basan en la incapacidad de TCP de discriminar cuándo la performance de la conexión ha disminuido debido a pérdidas en el enlace, común en las tecnologías wireless, y cuándo es debida a congestión en la red. El problema radica en que el transmisor no puede determinar con cierto grado de certeza qué ha motivado la pérdida de un segmento.
Cuatro aspectos inherentes a redes wireless pueden afectar
decisivamente la performance de TCP. Por un lado, el bit error rate (BER) del
medio físico, que como ya mencionamos, puede ser del orden de 1x10-6 o peor. En
segundo lugar, debemos considerar que el ancho de banda disponible es en
general menor al disponible en medio cableados. Una tercera componente es la
posible movilidad de los componentes de la red lo que puede implicar cambios
importantes en los tiempos de entrega de los segmentos. Finalmente, es común
que el protocolo de capa de Enlace y en particular de la sub-capa MAC así como
el protocolo de enrutamiento utilizado implique necesariamente tener un
overhead asociado a la movilidad y al aumento en la probabilidad de pérdida de
tramas o paquetes.
A los efectos de fijar ideas podemos considerar como ejemplo
de protocolo de sub-capa MAC a la familia de estándares de IEEE para Wireless
Local Area Network (WLAN). En ellos se especifica que para el envío de cada
trama de datos en el modo de operación Distributed Coordination Function (DCF)
se emplee un método de control de acceso al mediom denominado carrier sense
multiple access with collision avoidance (CSMA/CA), protocolo que busca reducir
la probabilidad de colisiones entre múltiples estaciones a través del evitado
de las mismas.
A los efectos
de detectar portadora, además del mecanismo clásico de “escucha del medio”
(detección física de portadora) se realiza una detección virtual de portadora
utilizando four-way handshake, donde con dos tramas de control (RTS: Request To
Send y CTS: Clear To Send) se reserva el medio, luego se envía la trama
conteniendo los datos y posteriormente se espera una trama de control ACK que
confirma su recepción. Lo anterior es una muestra clara del overhead
involucrado, pero hasta aquí no hemos considerado la movilidad de las
estaciones. Durante la misma, una estación móvil puede estar asociada a una
estación base (BS) a través de la cual recibe las tramas que provienen por
ejemplo de la red cableada y unos milisegundos después, deberá estar asociada a
otra estación base a la cual la primera deberá enviar las tramas que tuviera
almacenadas para dicha estación.
El modelo TCP/IP es un modelo de descripción de protocolos
de red desarrollado en los años 70 por Vinton Cerf y Robert
E. Kahn. Fue implantado en la red ARPANET, la primera red de área
amplia, desarrollada por encargo de DARPA, una agencia del Departamento de
Defensa de los Estados Unidos, y predecesora de la actual red Internet. EL
modelo TCP/IP se denomina a veces como Internet Model,
Modelo DoD o Modelo DARPA.
El modelo TCP/IP describe un conjunto de guías generales de diseño e
implementación de protocolos de red específicos para permitir que un equipo
pueda comunicarse en una red. TCP/IP provee conectividad de extremo a
extremo especificando cómo los datos deberían ser formateados, direccionados,
transmitidos, enrutados y recibidos por el destinatario. Existen
protocolos para los diferentes tipos de servicios de comunicación entre
equipos.
TCP/IP tiene cuatro capas de abstracción según se define en
el RFC 1122. Esta arquitectura de capas a menudo es comparada con
el Modelo OSI de siete capas.
El modelo TCP/IP y los protocolos relacionados son mantenidos por
la Internet Engineering Task Force (IETF).
Para conseguir un intercambio fiable de datos entre dos equipos, se deben
llevar a cabo muchos procedimientos separados.
El resultado es que el software de comunicaciones es complejo. Con un
modelo en capas o niveles resulta más sencillo agrupar funciones relacionadas e
implementar el software de comunicaciones modular.
Las capas están jerarquizadas. Cada capa se construye sobre su
predecesora. El número de capas y, en cada una de ellas, sus servicios y
funciones son variables con cada tipo de red. Sin embargo, en cualquier red, la
misión de cada capa es proveer servicios a las capas superiores haciéndoles
transparentes el modo en que esos servicios se llevan a cabo. De esta manera,
cada capa debe ocuparse exclusivamente de su nivel inmediatamente inferior, a
quien solicita servicios, y del nivel inmediatamente superior, a quien devuelve
resultados.
Capa
4 o capa de aplicación: Aplicación,
asimilable a las capas 5 (sesión), 6 (presentación) y 7 (aplicación) del
modelo OSI. La capa de aplicación debía incluir los detalles de las capas
de sesión y presentación OSI. Crearon una capa de aplicación que maneja
aspectos de representación, codificación y control de diálogo.
Capa
3 o capa de transporte: Transporte,
asimilable a la capa 4 (transporte) del modelo OSI.
Capa
2 o capa de internet: Internet,
asimilable a la capa 3 (red) del modelo OSI.
Capa
1 o capa de acceso al medio:
Acceso al Medio, asimilable a la capa 2 (enlace de datos) y a la capa 1
(física) del modelo OSI.